![[Python] 웹 스크래핑 #6](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FV1jNy%2FbtrVpnsuQXe%2FZA1KcXaxnC5NIe2VavfQP0%2Fimg.jpg)
이번 글에서는 Python에서 파일을 열고 파일에 내용을 쓰는 것이 얼마나 쉬운지 살펴볼 것이다
hello.py에서 전의 코드를 주석처리하고 다음의 코드를 집어넣는다
# wwr = extract_wwr_jobs(keyword)
# indeed = extract_indeed_jobs(keyword)
# jobs = indeed , wwr
-->file = open(f"{keyword}.csv", "w")그렇게 되면 hello.py와 같은 위치에 csv파일이 생성된다.

이번에 csv파일에 내가 원하는 데이터를 적어보겠다.
코드=>
더보기
from extractiors.wwr import extract_wwr_jobs
from extractiors.indeed import extract_indeed_jobs
keyword = input("What do you want to search for?")
wwr = extract_wwr_jobs(keyword)
indeed = extract_indeed_jobs(keyword)
jobs = indeed + wwr
file = open(f"{keyword}.csv", "w", encoding="utf-8")
file.write("Position,Company,Location,URL\n")
for job in jobs:
file.write(
f"{job['position']},{job['company']},{job['location']},{job['link']}\n"
)
file.close()아까 주석한 코드를 다시 풀고 결과를 보니 이렇게 잘 나왔다.

구글 드라이브에 저장해서 보니 이렇게 나왔다.

아마 데이터에 ,가 있나보다. 콤마를 없애주었다.
job_data = {
'link':f"https://www.indeed.com{link}",
'company':company.string,
'location':location.string,
'position':title
}
for a in job_data:
if job_data[a] != None:
job_data[a] = job_data[a].replace(",", " ")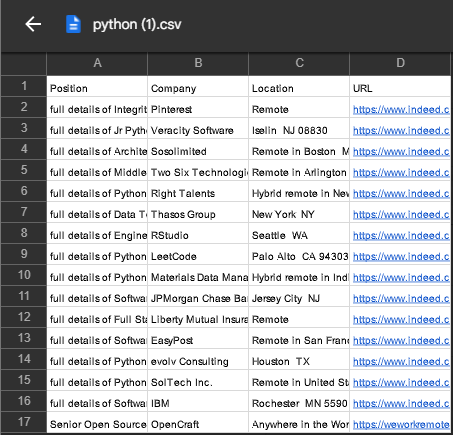
이렇게 해서 파이썬으로 웹스크래핑을 성공적으로 마쳤다. 다음은 플라스크를 다루면서 해볼 것이다.
전체코드
더보기
hello.py
from extractiors.wwr import extract_wwr_jobs
from extractiors.indeed import extract_indeed_jobs
keyword = input("What do you want to search for?")
wwr = extract_wwr_jobs(keyword)
indeed = extract_indeed_jobs(keyword)
jobs = indeed + wwr
file = open(f"{keyword}.csv", "w", encoding="utf-8")
file.write("Position,Company,Location,URL\n")
for job in jobs:
file.write(
f"{job['position']},{job['company']},{job['location']},{job['link']}\n"
)
file.close()indeed.py
from requests import get
#pip install requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
options = Options()
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
chrome_options = Options()
chrome_options.add_experimental_option("detach", True) #브라우저 꺼짐 방지 코드
browser = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options = chrome_options)
def get_page_count(keyword):
base_url = "https://kr.indeed.com/jobs?q="
end_url = "&limit=50"
browser.get(f"{base_url}{keyword}{end_url}")
soup = BeautifulSoup(browser.page_source, "html.parser")
#봇으로 인식해 차단 당해서 슬립시킴
time.sleep(5)
pagination = soup.find("nav", class_="ecydgvn0")
if pagination == None:
return 1
pages = pagination.find_all("div", recursive=False)
count = len(pages)
if count>= 5:
return 5
else:
return count
def extract_indeed_jobs(keyword):
pages = get_page_count(keyword)
print("Found",pages,"pages")
result = []
for page in range(pages):
base_url="https://www.indeed.com/jobs"
final_url = f"{base_url}?q={keyword}&start={page*10}";
print("Requesting ",final_url)
browser.get(final_url)
soup = BeautifulSoup(browser.page_source,"html.parser")
job_list = soup.find("ul", class_="jobsearch-ResultsList")
jobs = job_list.find_all('li',recursive=False)
for job in jobs:
zone = job.find("div", class_="mosaic-zone")
if zone == None:
anchor = job.select("h2 a")
title = anchor[0]['aria-label']
link = anchor[0]['href']
company = job.find("span", class_="companyName")
location = job.find("div", class_="companyLocation")
job_data = {
'link':f"https://www.indeed.com{link}",
'company':company.string,
'location':location.string,
'position':title
}
for a in job_data:
if job_data[a] != None:
job_data[a] = job_data[a].replace(",", " ")
result.append(job_data)
return resultwwr.py
from requests import get
from bs4 import BeautifulSoup
def extract_wwr_jobs(keyword):
base_url = "https://weworkremotely.com/remote-jobs/search?utf8=%E2%9C%93&term="
response = get(f"{base_url}{keyword}")
if response.status_code != 200:
print("Cannot request website")
else:
results = []
soup = BeautifulSoup(response.text, "html.parser")
jobs = soup.find_all("section", class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all("li")
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all("a")
anchor = anchors[1]
link = anchor["href"]
company, kind, region = anchor.find_all("span", class_="company")
title = anchor.find("span", class_="title")
job_data = {
'link': f"https://weworkremotely.com/{link}",
'company': company.string,
'location': region.string,
'position': title.string
}
for a in job_data:
if job_data[a] != None:
job_data[a] = job_data[a].replace(",", " ")
results.append(job_data)
return results-----------------------------------------
'Python > 웹 스크래핑' 카테고리의 다른 글
| [Flask] 웹 스크래핑 #8 (2) | 2023.01.05 |
|---|---|
| [Flask] 웹 스크래핑 #7 (0) | 2023.01.05 |
| [Python] 웹 스크래핑 #5 (0) | 2023.01.03 |
| [Python] 웹 스크래핑 #4 (0) | 2023.01.02 |
| [Python] 웹 스크래핑 #3 (0) | 2023.01.01 |