![[Python] 웹 스크래핑 #5](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FvuLYr%2FbtrVhTrU0S9%2F47eUisiF1c4uqasZCfAqd1%2Fimg.jpg)
저번 글에 이어서 계속 진행하겠다.
from requests import get
#pip install requests
from bs4 import BeautifulSoup
from extractiors.wwr import extract_wwr_jobs
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
options = Options()
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
chrome_options = Options()
chrome_options.add_experimental_option("detach", True) #브라우저 꺼짐 방지 코드
browser = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options = chrome_options)
browser.get("https://kr.indeed.com/jobs?q=python&limit=50")
soup = BeautifulSoup(browser.page_source, "html.parser")
job_list = soup.find("ul", class_="jobsearch-ResultsList")
jobs = job_list.find_all('li', recursive=False)
for job in jobs:
print(job)
print("////////////////////////////////")더보기를 눌러서 코드를 실행하게되면

이러한 결과가 나오게된다. 하지만 우리는 마지막에 mosaic-zone이라는 태그가 거슬린다.
왜냐하면 직업을 가지고 있지 않기 때문이다.
그렇기 때문에 job을 가지고 있지않은 친구인 mosaic를 None을 통해 if문으로 처리하겠다
None은 무언가가 있어야하는데 없다고 나타내주는 데이터 타입이다.
for job in jobs:
zone = job.find("div", class_="mosaic-zone")
if zone == None:
print("job li")
else:
print("mosaic li")이렇게 처리를 하게 되면 mosaic-zone을 잘 알아채고 있는 것을 알 수 있다.
이제 else문은 지워서 직업을 가지고 있는 li태그만을 신경써서 데이터를 추출해보자
자 anchor태그만을 출력하고 싶어져서 해보았다.
for job in jobs:
zone = job.find("div", class_="mosaic-zone")
if zone == None:
anchor = job.select("h2 a")
print(anchor)
print("////////////")
anchor에 성공적으로 접근했으니 직업게시물로 이동하는 링크인 href를 추출할 것이고 aria-label이라는 attribute(속성)를 추출할 것이다.
지금 콘솔에 찍힌 글들은 string이 아니라 딕셔너리 형태인 것 다들 아시죠? ㅎㅎ
전에 말했듯이 beautifulsoup는 우리가 찾은 html태그들을 데이터 구조로 변환 시킬 것이다.
for job in jobs:
zone = job.find("div", class_="mosaic-zone")
if zone == None:
anchor = job.select_one("h2 a")
title = anchor['aria-label']
link = anchor['href']
print(title,link)
print("......///////////")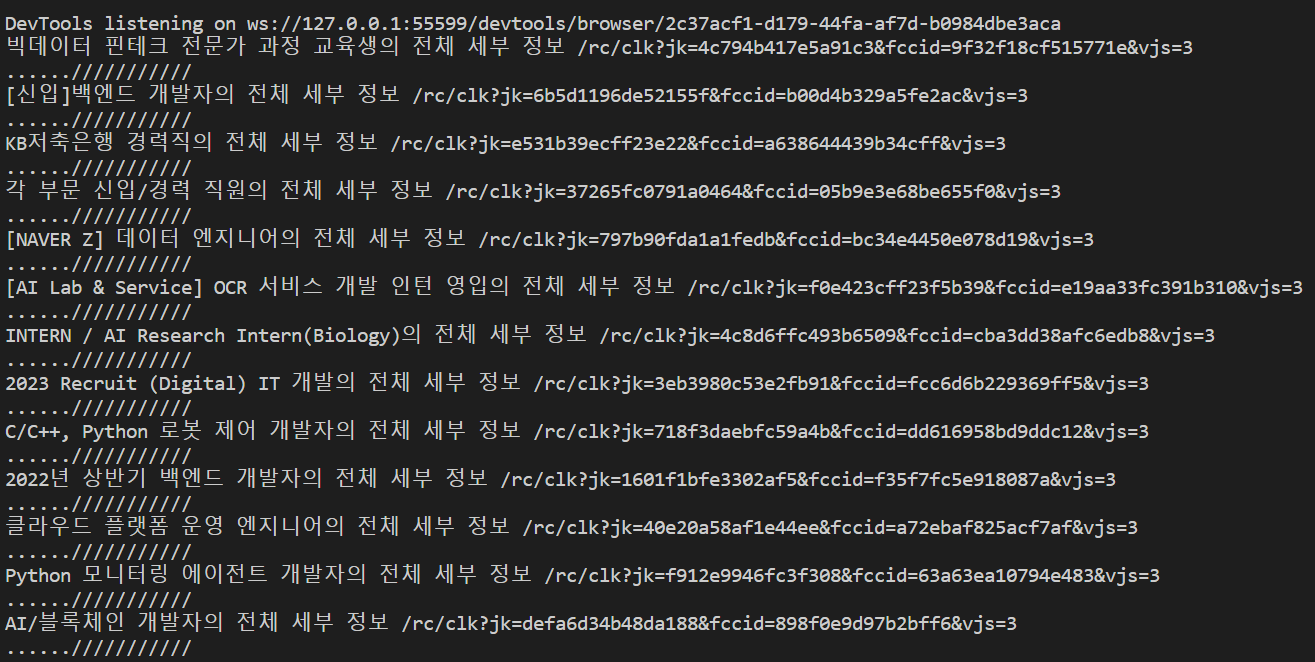
title이랑 link를 찾아내었으니 더 찾을 정보는 ?? 뭐 region company 정도 되겠다.
찾아보자

companyName과 companyLocation으로 제공하는 것을 알 수 있다.
우선 wwr.py로 가서 job_data를 보기 편하게 바꿔주자
job_data = {
'link':f"https://weworkremotely.com{link}",
'company': company.string,
'kind': kind.string,
'region': region.string,
}그리고
results =[]
for job in jobs:
zone = job.find("div", class_="mosaic-zone")
if zone == None:
anchor = job.select_one("h2 a")
title = anchor['aria-label']
link = anchor['href']
company = job.find("span",class_="companyName")
location = job.find("div",class_="companyLocation")
job_data={
'link':f"https://kr.indeed.com{link}",
'company':company.string,
'location':location.string,
'position':title,
}
results.append(job_data)
for result in results:
print(result)이렇게 result를 추가해주면 결과는 dictionary 형태로

잘 나오는 것을 볼 수 있다.
지금까지 잘 따라왔다면 궁금할 것이다.
페이지가 더있는데 그 데이터들은 어떻게 가져올까??
나는 요번에는 한 페이지에 5번 페이지까지 누를 수 있으니 5번 페이지까지 가져와보겠다.
만약 끝까지 간다면 arrow버튼의 위치를 알고 list의 끝까지가서 데이터를 알 수 있으나 너무 많은 정보니 딱 5페이지까지만 추출 해보겠다.
먼저 그 전에 코드를 수정을 조금 하겠다.
get_page_count()라는 function을 만들고
그 해당 검색어의 pagination의 갯수를 print해서 확인해보겠다.
코드
=>
from requests import get
#pip install requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
options = Options()
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
chrome_options = Options()
chrome_options.add_experimental_option("detach", True) #브라우저 꺼짐 방지 코드
browser = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options = chrome_options)
def get_page_count(keyword):
base_url = "https://kr.indeed.com/jobs?q="
end_url = "&limit=50"
browser.get(f"{base_url}{keyword}{end_url}")
soup = BeautifulSoup(browser.page_source, "html.parser")
pagination = soup.find("nav", class_="ecydgvn0")
if pagination == None:
return 1
pages = pagination.find_all("div", recursive=False)
print(len(pages))
get_page_count("python")
6이라고 나오면 되지 않기에 조금 수정하여 여러 검색어로 데이터를 추출해보았다.
if pagination == None:
return 1
pages = pagination.find_all("div", recursive=False)
count = len(pages)
if count>= 5:
return 5
else:
return count
print(get_page_count("python"))
print(get_page_count("nextjs"))
print(get_page_count("django"))
print(get_page_count("nestjs"))
print(get_page_count("java"))
print(get_page_count("c#"))
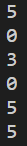
혹시 range를 기억하는지 모르겠다.
range는 for loop문 대신 간단하게 list를 만들어준다.
range를 이용하여 5개 페이지의 url을 받아올 것이다 url를 분석하니 페이지가 달라질때마다
이런식으로 start뒤에 숫자가 바뀌는 것을 알 수 있다.
코드
from requests import get
#pip install requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
options = Options()
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
chrome_options = Options()
chrome_options.add_experimental_option("detach", True) #브라우저 꺼짐 방지 코드
browser = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options = chrome_options)
def get_page_count(keyword):
base_url = "https://kr.indeed.com/jobs?q="
end_url = "&limit=50"
browser.get(f"{base_url}{keyword}{end_url}")
soup = BeautifulSoup(browser.page_source, "html.parser")
pagination = soup.find("nav", class_="ecydgvn0")
if pagination == None:
return 1
pages = pagination.find_all("div", recursive=False)
count = len(pages)
if count>= 5:
return 5
else:
return count
def extract_indeed_jobs(keyword):
pages = get_page_count(keyword)
print("Found",pages,"pages")
result = []
for page in range(pages):
base_url="https://www.indeed.com/jobs"
final_url = f"{base_url}?q={keyword}&start={page*10}";
print("Requesting ",final_url)
browser.get(final_url)
soup = BeautifulSoup(browser.page_source,"html.parser")
job_list = soup.find("ul", class_="jobsearch-ResultsList")
jobs = job_list.find_all('li',recursive=False)
for job in jobs:
zone = job.find("div", class_="mosaic-zone")
if zone == None:
anchor = job.select("h2 a")
title = anchor[0]['aria-label']
link = anchor[0]['href']
company = job.find("span", class_="companyName")
location = job.find("div", class_="companyLocation")
job_data = {
'link':f"https://www.indeed.com{link}",
'company':company.string,
'location':location.string,
'position':title
}
result.append(job_data)
return result
jobs = extract_indeed_jobs("python")
print(jobs)
print(len(jobs))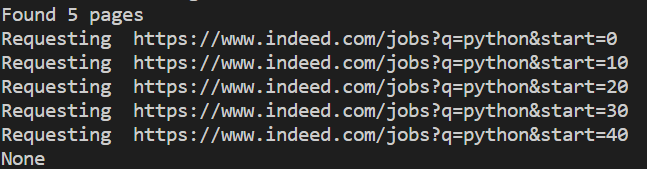
자 이제 사용자에게 키워드 입력을 받아보자
그러기 위해서는 바로위의 코드는 indeed.py라는 파일로 생성해주고 wwr.py라는 파일과 동일한 위치에 두고
hello.py에 keyword를 입력을 받는 방식으로 코드를 바꿔보겠다
전체코드
hello.py
#hello.py
from extractiors.wwr import extract_wwr_jobs
from extractiors.indeed import extract_indeed_jobs
keyword = input("What do you want to search for?")
wwr = extract_wwr_jobs(keyword)
indeed = extract_indeed_jobs(keyword)
jobs = wwr + indeed # +로 리스트 합치기
for job in jobs:
print(job)
print("////////////\n////////////")indeed.py
from requests import get
#pip install requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
options = Options()
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
chrome_options = Options()
chrome_options.add_experimental_option("detach", True) #브라우저 꺼짐 방지 코드
browser = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options = chrome_options)
def get_page_count(keyword):
base_url = "https://kr.indeed.com/jobs?q="
end_url = "&limit=50"
browser.get(f"{base_url}{keyword}{end_url}")
soup = BeautifulSoup(browser.page_source, "html.parser")
time.sleep(5)
pagination = soup.find("nav", class_="ecydgvn0")
if pagination == None:
return 1
pages = pagination.find_all("div", recursive=False)
count = len(pages)
if count>= 5:
return 5
else:
return count
def extract_indeed_jobs(keyword):
pages = get_page_count(keyword)
print("Found",pages,"pages")
result = []
for page in range(pages):
base_url="https://www.indeed.com/jobs"
final_url = f"{base_url}?q={keyword}&start={page*10}";
print("Requesting ",final_url)
browser.get(final_url)
soup = BeautifulSoup(browser.page_source,"html.parser")
job_list = soup.find("ul", class_="jobsearch-ResultsList")
jobs = job_list.find_all('li',recursive=False)
for job in jobs:
zone = job.find("div", class_="mosaic-zone")
if zone == None:
anchor = job.select("h2 a")
title = anchor[0]['aria-label']
link = anchor[0]['href']
company = job.find("span", class_="companyName")
location = job.find("div", class_="companyLocation")
job_data = {
'link':f"https://www.indeed.com{link}",
'company':company.string,
'location':location.string,
'position':title
}
result.append(job_data)
return resultwwr.py
from requests import get
from bs4 import BeautifulSoup
def extract_wwr_jobs(keyword):
base_url = "https://weworkremotely.com/remote-jobs/search?utf8=%E2%9C%93&term="
response = get(f"{base_url}{keyword}")
if response.status_code != 200:
print("Cannot request website")
else:
results = []
soup = BeautifulSoup(response.text, "html.parser")
jobs = soup.find_all("section", class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all("li")
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all("a")
anchor = anchors[1]
link = anchor["href"]
company, kind, region = anchor.find_all("span", class_="company")
title = anchor.find("span", class_="title")
job_data = {
'link': f"https://weworkremotely.com/{link}",
'company': company.string,
'location': region.string,
'position': title.string
}
results.append(job_data)
return results결과는?

성공적이다.
'Python > 웹 스크래핑' 카테고리의 다른 글
| [Flask] 웹 스크래핑 #7 (0) | 2023.01.05 |
|---|---|
| [Python] 웹 스크래핑 #6 (0) | 2023.01.05 |
| [Python] 웹 스크래핑 #4 (0) | 2023.01.02 |
| [Python] 웹 스크래핑 #3 (0) | 2023.01.01 |
| [Python] 웹 스크래핑 #2 (0) | 2023.01.01 |