![[Python] 웹 스크래핑 #2](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcmmORt%2FbtrU8FNjOyE%2FCxLRTKzrMnFg0FmP3bOSSK%2Fimg.jpg)
저번글에서 원하는 url에서 모든 html을 text로 가져와보았다.
하지만 내가 원하는 것은 원하는 정보만을 가져오는 것이다.
이번 글에서 그 작업을 해보겠다.
그러기 위해서는 BeautifulSoup이라는 라이브러리가 필요하다.
"혹시 설치가 안된분은 앞글을 참고하기 바란다"
https://lcm9243.tistory.com/75
[Python] 웹 스크래핑
웹 스크래핑이란 무엇일까? 웹페이지 상에는 엄청나게 많은 데이터들이 클라이언트들에게 보여지고 있다. 많은 사람들은 스크래핑과 크롤링을 같은 기술로 착각하는데 아니다. 엄연히 다른 기
lcm9243.tistory.com
이제 우리는 밑의 사진 처럼 이 많은 html text에서 jobs라는 class를 가진section을 찾을 것이다
그러고 나서 section안에 있는 ul안에서 li를 모두 찾을 것이다.
전체html코드가 궁금하신 분은 밑의 사이트에서 도구를 열어보시면 됩니다
https://weworkremotely.com/remote-jobs/search?term=python

바로 이 부분을 찾아낼 것이다.
이걸 어떻게 찾냐 바로 beautifulSoup에 findall을 이용할 것이다.
우선 연습으로 title태그를 가져오겠다.
from requests import get
#pip install requests
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?term="
serach_term ="python"
response = get(f"{base_url}{serach_term}")
if response.status_code != 200:
print("Can't request website")
else:
soup = BeautifulSoup(response.text, "html.parser")
#html.parser는 beautifulsoup에 html코드를 전송해주겠다는 뜻
print(soup.find_all('title'))성공적으로 title태그만 가져왔다!
이번에는 section태그에 id가 jobs인 친구만 가져와보겠다.
#윗문장을 아랫문장으로 고쳐주세요!
print(soup.find_all('title'))
-> print(soup.find_all('section',class_="jobs"))
성공적으로 가져왔다!
이번엔 job_section에서 for loop를 써서 li 부분만 뽑아보겠다.
from requests import get
#pip install requests
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?term="
serach_term ="python"
response = get(f"{base_url}{serach_term}")
if response.status_code != 200:
print("Can't request website")
else:
soup = BeautifulSoup(response.text, "html.parser")
#html.parser는 beautifulsoup에 html코드를 전송해주겠다는 뜻
jobs = soup.find_all('section',class_="jobs")
for job_section in jobs:
print(job_section.find_all('li'))
이렇게 li 부분만 잘 출력이 되는 것을 볼 수 있다.
이번엔 job post로 나누어 보겠다.
from requests import get
#pip install requests
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?term="
serach_term ="python"
response = get(f"{base_url}{serach_term}")
if response.status_code != 200:
print("Can't request website")
else:
soup = BeautifulSoup(response.text, "html.parser")
#html.parser는 beautifulsoup에 html코드를 전송해주겠다는 뜻
jobs = soup.find_all('section',class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
for post in job_posts:
print(post)
print("///////////////")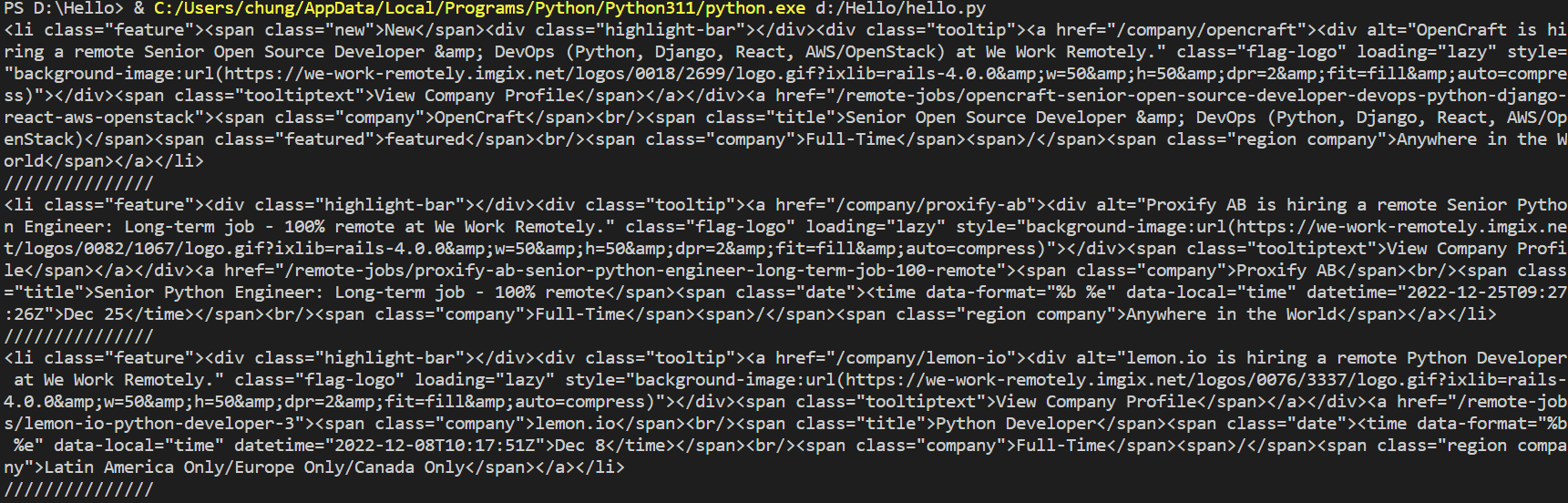
///////////////// <= "/"문자로 잘 나뉜 것을 볼 수 있다.
하지만 아직까지 마지막의 view-all이라는 class를 가진 li태그가 스크래핑 되고 있다. 이 html에선 모든 section태그에서 view-all이 마지막에 존재한다. 따라서 우리는 list의 마지막을 제거 해줄 것이다.
job_posts.pop(-1)이 문장을 추가해준다면 성공적으로 마지막 list를 제거할 수 있다.
이 모든 것은 아름다운 method를 가진 beautifulsoup 덕분이다!!
이번에는 더 들어가 li태그 안에 링크를 entity로 저장을 해보겠다.
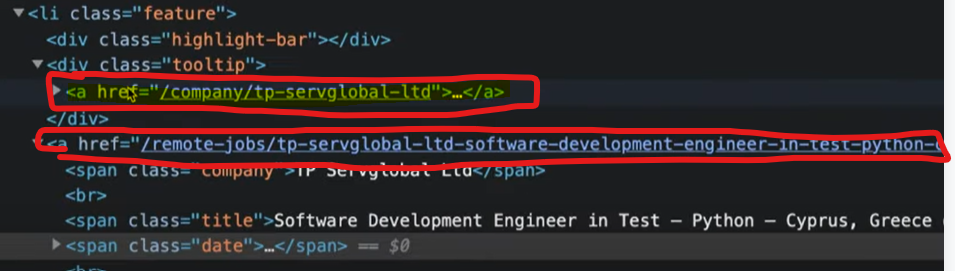
li 태그 안에 두 개의 링크가 있는데 아래 링크만 저장을 할 것이다.
from requests import get
#pip install requests
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?term="
serach_term ="python"
response = get(f"{base_url}{serach_term}")
if response.status_code != 200:
print("Can't request website")
else:
soup = BeautifulSoup(response.text, "html.parser")
#html.parser는 beautifulsoup에 html코드를 전송해주겠다는 뜻
jobs = soup.find_all('section',class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
print(anchor['href'])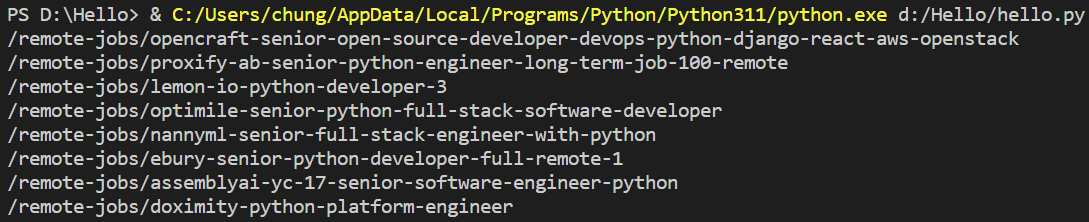
이렇게 두번째 a태그만 잘 나오는 것을 print 해보았다.
하지만 나는 이것을 엑셀에 저장하고 싶기에 변수에 저장한다.
link = anchor['href']그리고 company, kind, region의 3가지만 알고 싶기에 밑의 코드를 작성해준다.
company, kind, region = anchor.find_all('span', class_="company")
print(company, kind, region)이 문법은 list의 length를 맞추어주면 작동하는 문법이다.
company, kind, region에 0,1,2번째 리스트가 차례대로 들어간다.

그래서 이렇게 출력이 잘 되었다.
마지막으로 title이 필요하다
title = anchor.find_all('span', class_="title")
print(company, kind, region,title)
print("//////////")이 문장을 삽입해주고
title까지 출력을해주면?
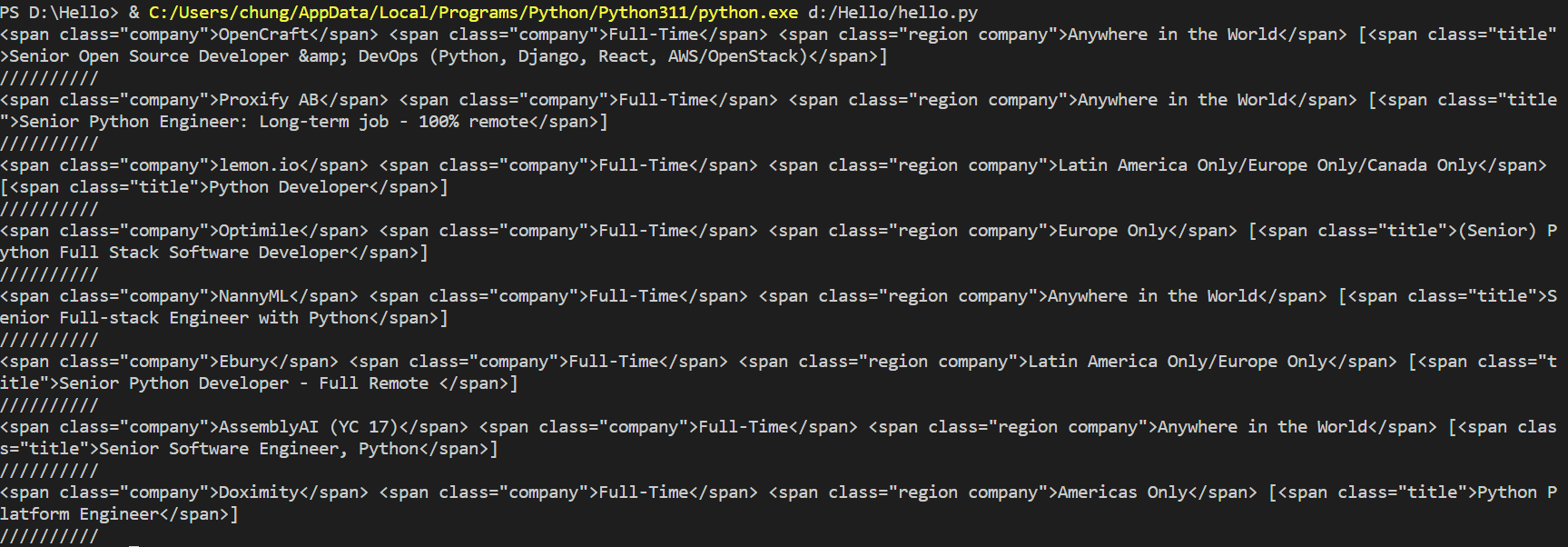
해당 job들을 모두 나누어 출력하였다.
정말 너무 쉬운 것 같다. html태그안의 글자들만 뽑으면 된다. 다음 글에서 이어서 보겠다.
전체코드
from requests import get
#pip install requests
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?term="
serach_term ="python"
response = get(f"{base_url}{serach_term}")
if response.status_code != 200:
print("Can't request website")
else:
soup = BeautifulSoup(response.text, "html.parser")
#html.parser는 beautifulsoup에 html코드를 전송해주겠다는 뜻
jobs = soup.find_all('section',class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all('span', class_="company")
title = anchor.find_all('span', class_="title")
print(company, kind, region,title)
print("//////////")'Python > 웹 스크래핑' 카테고리의 다른 글
| [Python] 웹 스크래핑 #6 (0) | 2023.01.05 |
|---|---|
| [Python] 웹 스크래핑 #5 (0) | 2023.01.03 |
| [Python] 웹 스크래핑 #4 (0) | 2023.01.02 |
| [Python] 웹 스크래핑 #3 (0) | 2023.01.01 |
| [Python] 웹 스크래핑 #1 (0) | 2022.12.31 |