![[Python] 웹 스크래핑 #3](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbgI7Bz%2FbtrU8EgDkoB%2FHEQxLCOx8bySoyEgIS8kok%2Fimg.jpg)
저번 [Python] 웹 스크래핑 #2 글까지 잘 따라왔다면
아래 코드와 같이 출력이 되었다
더보기
<span class="company">OpenCraft</span> <span class="company">Full-Time</span> <span class="region company">Anywhere in the World</span> [<span class="title">Senior Open Source Developer & DevOps (Python, Django, React, AWS/OpenStack)</span>]
//////////
<span class="company">Proxify AB</span> <span class="company">Full-Time</span> <span class="region company">Anywhere in the World</span> [<span class="title">Senior Python Engineer: Long-term job - 100% remote</span>]
//////////
<span class="company">lemon.io</span> <span class="company">Full-Time</span> <span class="region company">Latin America Only/Europe Only/Canada Only</span> [<span class="title">Python Developer</span>]
//////////
<span class="company">Optimile</span> <span class="company">Full-Time</span> <span class="region company">Europe Only</span> [<span class="title">(Senior) Python Full Stack Software Developer</span>]
//////////
<span class="company">NannyML</span> <span class="company">Full-Time</span> <span class="region company">Anywhere in the World</span> [<span class="title">Senior Full-stack Engineer with Python</span>]
//////////
<span class="company">Ebury</span> <span class="company">Full-Time</span> <span class="region company">Latin America Only/Europe Only</span> [<span class="title">Senior Python Developer - Full Remote </span>]
//////////
<span class="company">AssemblyAI (YC 17)</span> <span class="company">Full-Time</span> <span class="region company">Anywhere in the World</span> [<span class="title">Senior Software Engineer, Python</span>]
//////////
<span class="company">Doximity</span> <span class="company">Full-Time</span> <span class="region company">Americas Only</span> [<span class="title">Python Platform Engineer</span>]
//////////이번 글에서는 span태그를 없애고 그 안의 정보를 출력해볼 것이다.
from requests import get
#pip install requests
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?term="
serach_term ="python"
response = get(f"{base_url}{serach_term}")
if response.status_code != 200:
print("Can't request website")
else:
soup = BeautifulSoup(response.text, "html.parser")
#html.parser는 beautifulsoup에 html코드를 전송해주겠다는 뜻
jobs = soup.find_all('section',class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all('span', class_="company")
title = anchor.find('span', class_="title")
print(company.string, kind.string, region.string, title.string)
print("//////////")그러기 위해서 title변수의 anchor.find_all ==> anchor.find로 바꾸어 주고
.string을 모두 붙여주어
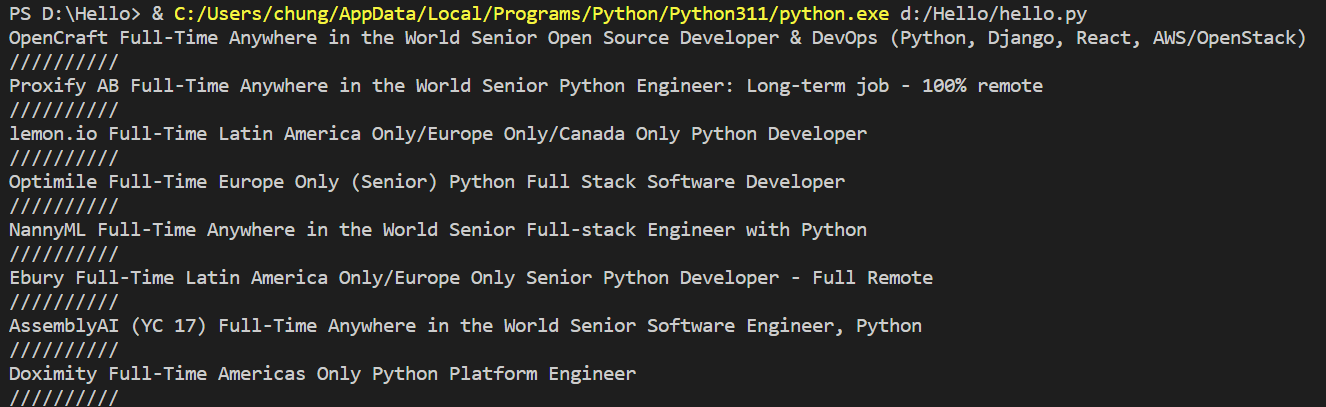
이렇게 원하는 결과가 딱!
이제 이 데이터를 저장을 해보자
그러기 위해 dictionary를 이용하여 만들어 저장전에 출력해보겠다.
더보기
from requests import get
#pip install requests
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?term="
serach_term ="python"
response = get(f"{base_url}{serach_term}")
if response.status_code != 200:
print("Can't request website")
else:
result =[]
#job_data 저장할 공간
soup = BeautifulSoup(response.text, "html.parser")
#html.parser는 beautifulsoup에 html코드를 전송해주겠다는 뜻
jobs = soup.find_all('section',class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all('span', class_="company")
title = anchor.find('span', class_="title")
job_data = {
'company': company.string,
'kind': kind.string,
'region': region.string,
}
result.append(job_data)
#job_data를 추출할때마다 result에 넣는다
print(result)
이렇게 dictionary로 가득찬 리스트를 만들어보았다. 조금 더 가공하여 밑의 사진처럼 만들어보았다.
더보기
from requests import get
#pip install requests
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?term="
serach_term ="python"
response = get(f"{base_url}{serach_term}")
if response.status_code != 200:
print("Can't request website")
else:
results =[]
soup = BeautifulSoup(response.text, "html.parser")
#html.parser는 beautifulsoup에 html코드를 전송해주겠다는 뜻
jobs = soup.find_all('section',class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all('span', class_="company")
title = anchor.find('span', class_="title")
job_data = {
'company': company.string,
'kind': kind.string,
'region': region.string,
}
results.append(job_data)
#job_data를 추출할때마다 result에 넣는다
for result in results:
print(result)
print("--------------------------------")
serach_term이라는 변수에 java, react, etc... 원하는 string으로 변경하면 즉각 다른 데이터가 출력된다
이제 파일에 넣어보자
우선, 새로운 폴더와 파일을 만들어주자
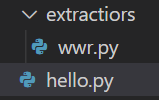
그 후 전의 코드를 extract_wwr_jobs라는 function을 생성해 담아주자
더보기
from requests import get
#pip install requests
from bs4 import BeautifulSoup
def extract_wwr_jobs(keyword):
base_url = "https://weworkremotely.com/remote-jobs/search?term="
serach_term ="python"
response = get(f"{base_url}{serach_term}")
if response.status_code != 200:
print("Can't request website")
else:
results =[]
soup = BeautifulSoup(response.text, "html.parser")
#html.parser는 beautifulsoup에 html코드를 전송해주겠다는 뜻
jobs = soup.find_all('section',class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all('span', class_="company")
title = anchor.find('span', class_="title")
job_data = {
'company': company.string,
'kind': kind.string,
'region': region.string,
}
results.append(job_data)
#job_data를 추출할때마다 result에 넣는다
for result in results:
print(result)
print("--------------------------------")이렇게 담았다면
serach_term 변수를 삭제해주고
새로 받을 keyword함수를 위해
response = get(f"{base_url}{keyword}")이렇게 변경해준다
또 for loop문도 그저 프린트가 아닌 return으로 반환을 해줄 것이다.
for result in results:
print(result)
print("--------------------------------")
==> return results그리고 hello.py 파일에
from requests import get
#pip install requests
from bs4 import BeautifulSoup
from extractiors.wwr import extract_wwr_jobs
extract_wwr_jobs
jobs = extract_wwr_jobs("python")
print(jobs)코드 작성을 해주면 wwr.py에서 return을 해준 값이
고대로~ 출력이 되는 것을 볼 수 있다.

이제 다음 글은 indeed.com에 가서 저장을 해볼 것이다.
정말 쉽다.. ㅎㅎ
'Python > 웹 스크래핑' 카테고리의 다른 글
| [Python] 웹 스크래핑 #6 (0) | 2023.01.05 |
|---|---|
| [Python] 웹 스크래핑 #5 (0) | 2023.01.03 |
| [Python] 웹 스크래핑 #4 (0) | 2023.01.02 |
| [Python] 웹 스크래핑 #2 (0) | 2023.01.01 |
| [Python] 웹 스크래핑 #1 (0) | 2022.12.31 |